
Extract Solana transactions directly from Turbine shreds — before the RPC gets involved, with Yellowstone-compatible gRPC filters

“Speed is everything on Solana.” ⚡
For sniping bots, MEV searchers, and high-frequency trading systems, the difference between a winning and a losing trade comes down to milliseconds — and those milliseconds are determined by one thing: how early your application sees a transaction.
Standard gRPC streams sit behind the RPC. Every transaction your application receives has already travelled the full path — from the validator, through the RPC, through the entire Replay stage, through the Geyser plugin — before it reaches you. Signature verification, BPF execution, account state updates, log compilation — while the RPC works through all of that, the transaction has already existed on the network in a form your application never saw. That form is called a shred — tiny packets broadcast by the block leader the moment a block is being produced, before the RPC touches anything, before a single line of BPF code has run.
RabbitStream intercepts data before any of that. It listens to raw UDP shreds directly from multiple sources — no RPC involved, no execution pipeline, no waiting. You see the transaction at the earliest point it exists on the network.
How the Solana pipeline works?
When a validator receives transactions from the network, it runs them through a sequential pipeline. The block leader first breaks the block into shreds — which are small, fixed-size packets, and broadcasts them across the network via the Turbine protocol. Receiving validators reassemble these shreds in the Blockstore stage, recovering any missing pieces using Reed-Solomon erasure coding. Only after a complete set of shreds has been reassembled does the validator move to the Replay stage — where transactions are signature-verified, executed by the SVM (Solana Virtual Machine), account states are updated, and logs are written.
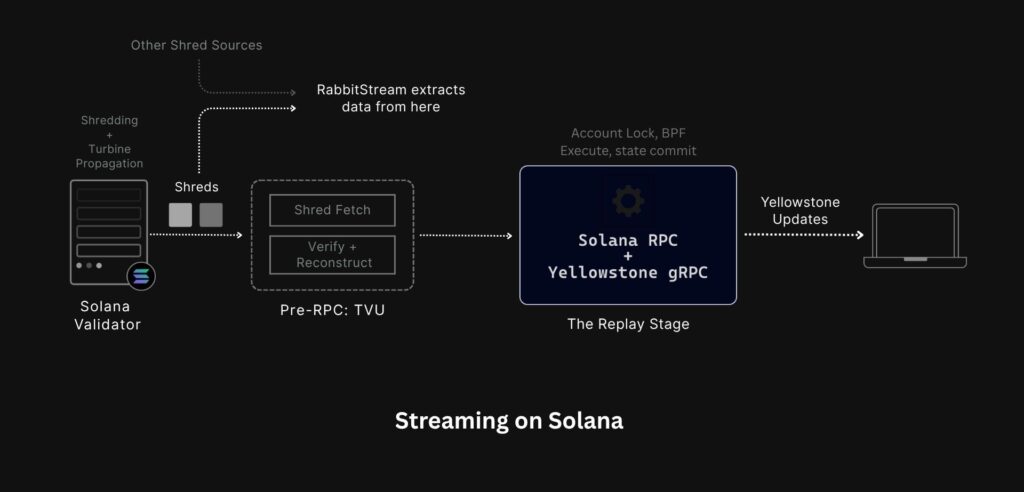
Geyser plugins, which power streams like Yellowstone gRPC, sit at the end of this pipeline — emitting transaction data only after the Replay stage has completed. By that point, the transaction has been on the network for tens of milliseconds.
What is RabbitStream?
RabbitStream is a transaction stream that delivers data directly from raw UDP shreds — before transactions ever hit the RPC.
Most developers think of transaction data as something that flows through an RPC. With RabbitStream, that mental model doesn’t apply. RabbitStream doesn’t sit inside a validator or plugin into an RPC node. It independently listens to raw UDP shreds straight from multiple sources, performs its own shred reconstruction and validation, and streams decoded transactions directly to your application — without touching any RPC node at any point.
The RPC is never in the picture. Not bypassed — simply not involved. By the time any RPC node has even received the shreds, RabbitStream has already delivered the transaction to your backend.
But speed without usability isn’t enough. Raw shreds are binary-encoded and arrive with no filtering — meaning without RabbitStream, you’d have to decode everything yourself just to find the transactions you care about. RabbitStream removes that burden entirely. Transactions are decoded server-side and delivered through a Yellowstone-compatible gRPC interface — same SubscribeRequest format, same accountInclude and accountRequired filters you already use. Structured, readable, and filtered down to exactly what your application needs.
Shred-stage speed. Before the RPC. Yellowstone-style filtering.
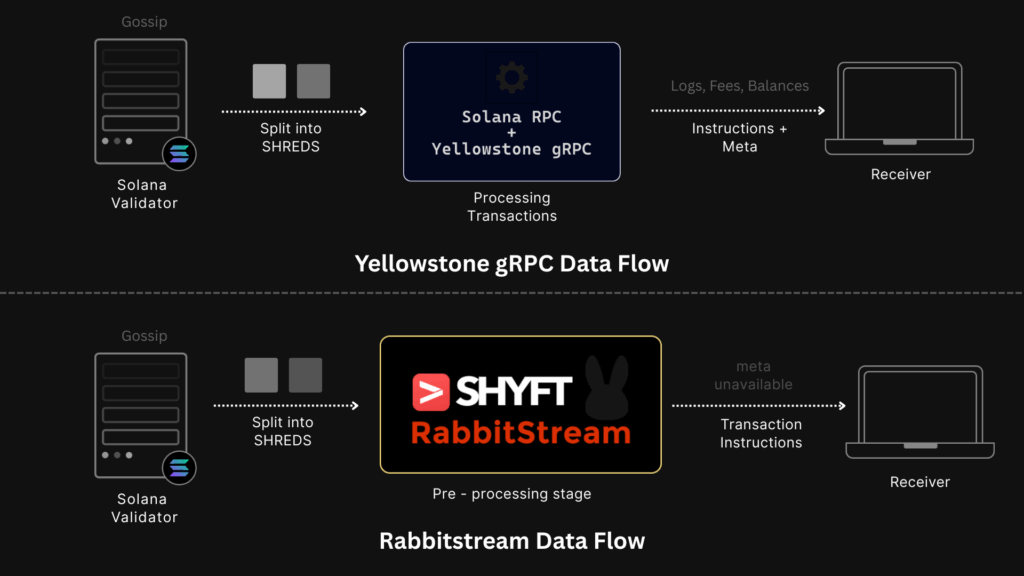
An important distinction: Yellowstone gRPC is a Geyser plugin that runs inside an RPC node. It is bound to that node’s execution pipeline — it can only emit data after the node has fully replayed the transaction.
RabbitStream is entirely separate. It runs independently of any RPC node, listening directly to the UDP shred layer of the Solana network. These are architecturally different approaches — not just the same thing tapping at a different stage.
The Problem with Raw Shreds
Shreds are fast, but consuming them directly is painful:
- No filtering — you receive every transaction on Solana, unfiltered, including votes and failures.
- Binary encoded — incompatible with standard Solana libraries. You need custom decoding logic just to read them.
- No structure — raw shreds must be reassembled, erasure-decoded, and parsed before they’re usable.
RabbitStream handles all of that server-side. Shreds are decoded, reconstructed, and filtered before they reach your application — using the exact same SubscribeRequest format as Yellowstone gRPC.
Same filters. Same subscription format. Just faster.
Note: To maximise coverage and reliability, RabbitStream doesn’t rely on a single shred source. It ingests shreds from multiple sources across the network simultaneously — ensuring the earliest possible delivery regardless of which path the shreds take.
RabbitStream: What’s Included and What Isn’t
RabbitStream delivers transactions before execution — which means only transaction filters are supported. Filters that depend on confirmed or post-execution data are not available.
This is a deliberate trade-off. Supporting account, block, or slot filters would require waiting for the RPC to confirm and compile that data — the same wait that costs you those critical milliseconds. This means two things:
- No Execution Metadata – Fields like logs, inner instructions, and error details are generated during the Replay stage. Since RabbitStream delivers data before that stage runs, these fields are simply not available yet.
- Transaction filters only – Filters for
accounts,blocks,slots, andblocksMetaall depend on data that is confirmed and compiled by the RPC node after execution. Since RabbitStream never touches the RPC, only transaction filters are supported.
| Filter Type | Yellowstone gRPC | RabbitStream |
|---|---|---|
| transactions | ✅ | ✅ |
| accounts | ✅ | ❌ |
| slots | ✅ | ❌ |
| blocks | ✅ | ❌ |
| blocksMeta | ✅ | ❌ |
| accountsDataSlice | ✅ | ❌ |
| Lookup Tables (LUTs) | ✅ | ❌ |
For most speed-critical strategies, the missing metadata doesn’t matter. Think about it — when you’re sniping a token launch, you don’t need the logs. You just need to see the transaction before everyone else does. When you’re chasing an arbitrage opportunity, you don’t need to wait for the execution result. By the time that result is available, the window is already closing. The edge isn’t in knowing what happened. It’s in seeing it first.
If you need the full execution context — logs, error details, confirmed state — use Yellowstone gRPC. Many strategies use both: RabbitStream to act fast, Yellowstone to confirm the outcome.
Speed Benchmarks
We ran a head-to-head comparison between RabbitStream and Jito Shredstream across 10,000 transactions to see which stream delivered the first signal faster.
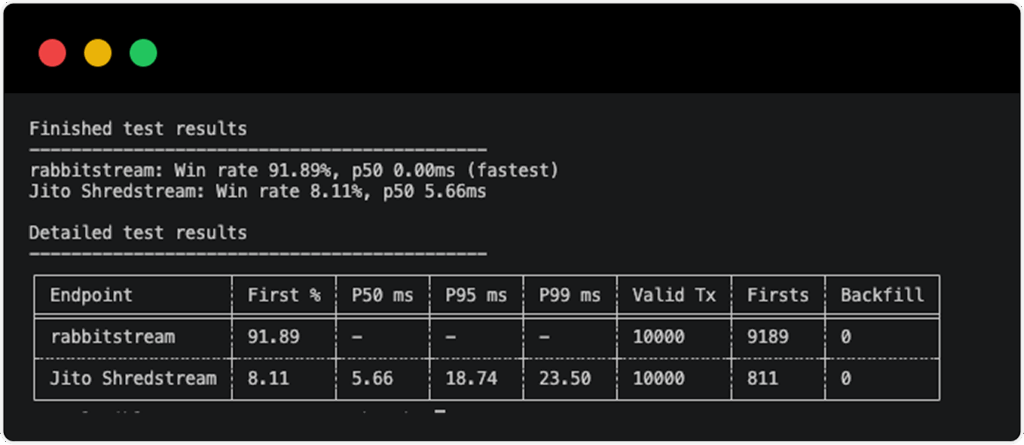
RabbitStream won first delivery in 91.89% of all runs — arriving ahead of Jito Shredstream in nearly 9 out of every 10 transactions. Jito Shredstream claimed first delivery in just 8.11% of runs, with a p50 of 5.66ms, p95 of 18.74ms, and p99 of 23.50ms.
RabbitStream’s p50 registered at 0.00ms against Jito Shredstream — meaning in the majority of cases, RabbitStream arrived so far ahead that the difference was below measurable threshold.
When to Use RabbitStream
Use RabbitStream when:
- You’re sniping token launches (Pump.fun, Raydium, Orca)
- You’re detecting MEV or arbitrage opportunities
- You need the fastest transaction signal possible
Use Yellowstone gRPC when:
- You need execution logs and inner instructions
- Data completeness matters more than speed
Quick Start
RabbitStream is fully compatible with your existing Yellowstone gRPC client. Same SubscribeRequest format, same auth token — the only change is the endpoint URL. See it in action:
#[tokio::main]
async fn main() -> anyhow::Result<()> {
env::set_var(
env_logger::DEFAULT_FILTER_ENV,
env::var_os(env_logger::DEFAULT_FILTER_ENV).unwrap_or_else(|| "info".into()),
);
env_logger::init();
let args = Args::parse();
let zero_attempts = Arc::new(Mutex::new(true));
retry(ExponentialBackoff::default(), move || {
let args = args.clone();
let zero_attempts = Arc::clone(&zero_attempts);
async move {
let mut zero_attempts = zero_attempts.lock().await;
if *zero_attempts {
*zero_attempts = false;
} else {
info!("Retry to connect to the server");
}
drop(zero_attempts);
let client = args.connect().await.map_err(backoff::Error::transient)?;
info!("Connected");
let request = args.get_txn_updates().map_err(backoff::Error::Permanent)?;
geyser_subscribe(client, request)
.await
.map_err(backoff::Error::transient)?;
Ok::<(), backoff::Error<anyhow::Error>>(())
}
.inspect_err(|error| error!("failed to connect: {error}"))
})
.await
.map_err(Into::into)
}This snippet shows the core subscription setup. For the complete code, Please check our Rabbistream Docs. You can also explore more examples on our GitHub here.
Conclusion
Solana moves fast, and the data layer feeding your application needs to keep up. RabbitStream gives you the earliest possible transaction signal on the network — extracted directly from shreds, before the RPC gets involved, with the same Yellowstone-style filters you already know. The speed advantage is real.
The integration effort is minimal. And for strategies where seeing it first is everything — that combination is hard to beat.
Quick Start Guide: Getting started with RabbitStream takes less than a minute if you’re already on Yellowstone gRPC. Point your existing client at the RabbitStream endpoint, keep your `SubscribeRequest` filters exactly as they are, and you’re live.
- 📄 How to get started with RabbitStream →
- 💻 Example Code for Token Detection using RabbitStream on GitHub →
Same filtering as Yellowstone. Just faster. ⚡
You can explore our other related articles: Streaming Real-Time Data on Solana, or Shreds vs Yellowstone gRPC on Solana
